23년 1월 23일 모각코
계획 -> 딥러닝 기초(최적화의 주요개념)
학습내용 ->
- Generalization

Generalization이 좋다 = 성능이 학습 데이터와 비슷하게 나올거다
하지만 학습데이터의 성능 자체가 안좋으면 Generalization performance가 좋다고 해서 테스트 데이터의 성능이 좋다고 할 수 없다.
- Underfitting과 Overfitting
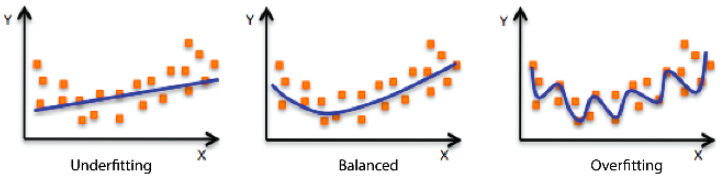
학습데이터에 대해 잘 동작하지만 테스트 데이터에 대해 잘 동작하지 않는 현상을 Overfitting
네트워크가 너무 간단하거나 트레이닝을 조금 시켜서 학습 데이터를 잘 못맞추는 현상을 Underfitting
- Cross-validation

학습데이터와 validation 데이터를 k개로 나눠서 k-1개로 학습을 시키고 나머지 한개로 validation을 해보는 것
테스트 데이터가 학습에 사용되어서는 안됨. 학습에는 무조건 학습데이터와 validation데이터만을 활용해야 함
- Bias and Variance
Variance란 어떤 비슷한 입력을 넣었을때 출력이 얼마나 일관적으로 나오는지
Bias란 출력을 평균적으로 볼때 얼마나 true target에 접근하는지
- Bias and Variance Tradeoff
학습데이터에 노이즈가 끼어있다고 가정했을때

t는 target, f hat은 neural network의 출력값
cost를 minimize한다는 것은 bias를 minimize하는것, variance를 minimize하는것, noise 이 세가지로 나뉨
bias를 줄이면 variance가 높아질 가능성이 크고, variance를 줄이면 bias가 높아질 가능성이 큼
- Bootstrapping
학습데이터가 고정되어 있을 때(예를 들어 100개) 그 안에서 random subsampling(100개중에 80개)을 통해서 학습데이터를 여러개를 만들고 각각을 이용하여 여러 모델을 만들어서 무언가를 하겠다.
- Bagging과 Boosting

Bagging
여러개의 모델을 random subsampling을 통해 만들고, 여러 모델들의 각각의 ouput을 어떤식으로 평균을 내겠다.
boosting
학습 데이터가 100개가 있으면 이 중에서 sequential 하게? 바라봐서 모델 하나를 간단하게 만들고, 이 모델을 학습 데이터에 대해 돌려봄. 80개에 대해서는 예측을 잘하지만 20개에 대해서는 예측을 잘 못할 수도 있음. 이때 예측이 잘 안되는 20개의 데이터에 대해서만 잘 동작하는 두 번째 모델을 하나 만듦. 이렇게 여러 개의 모델들을 만들어서 합침. 하나하나의 모델들(weak learner)을 sequential하게 합쳐서 strong learner을 만듦